Note – the first post (Notes about the AWS JDK) can be found here

Keynote speech by Andy Jassy (Sr. Vice President, Amazon Web Services)
He also announced that ‘House of Cards’ w/ Kevin Spacey is coming out in Feb!
AWS is all about innovation
82 significant innovations introduced in 2012
158 new services
Amazon Redshift
http://aws.amazon.com/redshift
SAPSAP HANA One on AWS at $ 0.99/hr Dev Edition
Data Planner
Integrated with other AWS services
Uses UI to drag-n-drop components
Connect logs generated to S3, EMR
It has scheduler and pre-conditions
They use the same ‘pipeline’ term
Can run ‘bash’ scripts stored in S3
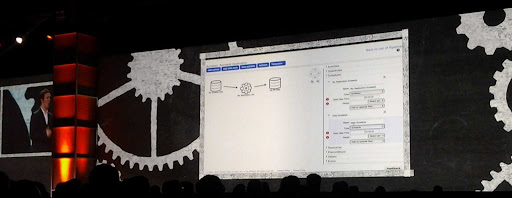
Update: This has now been officially launched as the Data Pipeline, which is an exciting validation of SnapLogic‘s concept of integration flows as Snaps and Pipelines (see here)
… and low prices
Key strategic objective is to facilitate Enterprise migration to cloud
Amazon VPC + Direct Connect + Route 53
Elastic Load Balancing
Dynamo DB is the fastest growing service in the history of AWS
Java AWS SDK for Eclipse
Web UI frontend
EC2 back-end workers
S3 for the data storage
DynamoDB for metadata
SQS to distribute workload among workers
Suitable for CPU intensive apps, where processing must not be executed in the context of the Web UI
All this can be done via Eclipse AWS SDK
- Can manage multiple aws accounts
- Creates sample code working out of the box
- Explorer view to manage all supported services
In particular, you can see all S3 buckets, and explore its contents (including virtual directories); drag-and-drop works to/from the local filesystem
(note after upload, only owner can see — web ui can’t access: right click and set permission)
Explorer shows the tables on DynDb, create new tables, edit r/w capacity
DynDb editor shows just a page of results by default; can add a ‘scan condition’ to filter only a certain subset
Changes must be ‘saved’ to the actual db (using std ‘save’ cmd)
Can also execute remote debugging against a running instance.
CloudWatch
Can monitor and set thresholds for alarms/notifications
alerts can also take actions to scale up instances
Custom metrics (uses a ReST PUT API) — also can use scripts (search on G)
Stores 2-weeks worth of information, data can be pulled and pushed into long-term storage, analysis, map-reduce…
Asperatus (3rd party lib to push metrics)
Aws-java-sdk
Integrates with logging and JMX
Convention over configurarion
Reports metrics by instanceId/AppName
Can also use a Logger (reports class, err msg)
Easy JMX integration
Deployed on the front-end to measure ‘true’ latency perceived by clients
BigData with Spark/Shark
AMP Lab at Berkley Uni: htpp://amplab.cd.berkley.edu
see Mesos — cluster virtualization mgr (Twitter uses it for 2,500 VMs in prod)
BlinkDB — approximate querying system (ML)
Spark is a fast, distributed MapReduce-like engine (using in-memory storage)
General execution graphs
Supports HDFS/S3/etc
messages = spark.textfile(“hdfs://…”)
errors = messages.filter(_.startsWith(“ERROR”)
creates an RDD (resilient data distribution? )
Shark — port of Apache Hive to Spark
Compatible with existing Hive meta store and HDFS data
Dynamic join algo selection (done in real-time at query time)
About 100 times faster than Hive on Hadoop, even unstructured data
with GROUP BY (mandatory? ) takes a bit longer, but still 50x
CloudFront (AWS Content Distribution Network)
When benchmarked for latency, CloudFront is 1st or 2nd v. Other CDN in US and other regions
Uses S3 for caching of content, with a Load Balancer in front, allows deployment to multiple Availability Zones (AZs) to offer HA.
Index service separate from Storage
Version Upgrade (the `new` way)
- light up a couple of ‘canaries’ with the new version and start routing some traffic to them; check for catastrophic (and not-so-catastrophic) failures, bugs, etc.
- once the ‘canaries’ survive, start deploying new instances with the new release and turn off the ones with the old – always keeping an eye on traffic, failures, latency, etc.
- if all goes well, one has managed a pretty serious upgrade cycle (with possibly thousands of nodes) without any downtime at all, and the users barely noticing a thing (if at all).
- again, use ‘canaries’ (if you are doing cloud deployments and don’t believe in staging, about time to start looking for a new job);
- leave the existing cluster alone, however, and just deploy an entire new one with the new release – once ready, just ‘flip the switch’ on your ELB and the new cluster starts serving traffic;
- anything serious happens, ‘flip the switch’ back, and you’re back in the stable configuration;
- rinse and repeat, until the new release is stable and serving traffic within the operational parameters (but, really, if you have to do this more than twice, it’s about time to find yourself a better dev team)
- Keep the ‘old version’ cluster around for a few days, just in case: the expenditure is minimal, and infinitely worth it if an emergency rollback is necessary.
Design Architecture with your customers in mind, then use ‘late binding’ to pick which infrastructure serves you best
Deploying Python apps using BeanStalk
source ./venv1/bin/activate (as usual)
To create the reqts use pip freeze >requirements.txt
pip -r requirements.txt
eb is a command-line tool to manage beanstalk
eb init
To create the env – generates the info to create it then use
eb start
to actually deploy and get it start.
eb status
to check status.
There is also an ini file that is read in ~/.elasticbeanstalk
git aws.push
It also allows to drive AWS AutoScaling triggers to start new EC2s (behind a LB); look for:
.ebextensions/python.config
Overall it seemed like an interesting tool (the talk really went too fast to take any meaningful notes), I recommend reading the documentation here.

Leave a comment