This is the third and final part of a three-part series: Part 1 describes the required setup and how to get Apache Mesos Master and Agent running in two Vagrant VMs; Part 2 shows how to connect to the HTTP API and accept resource offers.

This series is an extended (and updated) version of the [talk] I gave at MesosCon Europe 2015 updated for Apache Mesos 1.0.0, which has just been released (August 2016) – you can also find the [slides] there.
Recap
By the end of the last part, we had a running “framework” connected to a Mesos Master via the HTTP API, with an open (“subscribed”) connection, running in a background thread, and uniquely identified by a Stream-id:
Connecting to Master: http://192.168.33.10:5050/api/v1/scheduler
body type: SUBSCRIBE
The background channel was started to http://192.168.33.10:5050/api/v1/scheduler
Stream-id: 31e0c731-f055-4588-b0f0-5cdfaed5260c
Framework 474970d2-1b5e-40f9-82a2-135c71cd1448-0000 registered with Master at (http://192.168.33.10:5050/api/v1/scheduler)
Further, we had just been offered resources from the running Agent, via the Master:
{"offers": [
{...
"attributes": [ {
"name": "rack",
"text": {
"value": "r2d2"
},
"type": "TEXT"
},
{
"name": "pod",
"text": {
"value": "demo,dev"
},
"type": "TEXT"
}
],
...
"resources": [
{
"name": "ports",
"ranges": {
"range": [ {"begin": 9000, "end": 10000}]
},
{
"name": "cpus",
"role": "*",
"scalar": {"value": 2.0},
},
{
"name": "mem",
"role": "*",
"scalar": {"value": 496.0},
},
{
"name": "disk",
"role": "*",
"scalar": { "value": 4930.0 },
}
],
...
] }
Next, we are going to use some of these resources to launch a container on the Agent.
Accepting Offers
Although recently Mesos has evolved its model to allow frameworks to pre-emptively reserve resources and sort of stash them aside for peak demands (or launching high-priority workloads), as well as for “best-effort” allocation of unused resources to low-priority tasks, which wouldn’t mind being booted out of those reserved resources are claimed by their rightful owners, we will not address those use cases here.
For those interested, I would recommend reading the Reservation and Oversubscription documents, as well as follow the development activity on the Mesos mailing lists: both features have been introduced only recently and are likely to continue evolving in the feature.
Obviously, if there is enough interest in such topics, we could be convinced to write a dedicated series on the subject…
At any rate, to “accept” offers, all we need to do is to tell Master what we would like to do with them (namely, run an Ngnix container) and how much of what’s been offered we’d like to take (in a shared, high load environment such as a Production Data Center, it is usually good manners only to use as little, or as much, as actually needed, and rely on the “elasticity” of the underlying resources, to deal with sudden increases in load).
The file resources/container.json has the full body of the request (of type ACCEPT) that we will send to Master; as you can see, several fields are marked as null, because they contain dynamically generated values that we need to fill in so that Master can reconcile our request with how many offers, frameworks and tasks it has pending – in a realistic production environment, a Mesos Master could be handling upwards of hundreds of frameworks, thousand of Agents and many tens of thousand tasks (even though, actually the tasks are managed by the Agents themselves).
container_launch_info = get_json(DOCKER_JSON)
# Need to update the fields that reflect the offer ID / agent ID and a random, unique task ID:
task_id = str(random.randint(1, 100))
agent_id = offers.get('offers')[0]['agent_id']['value']
offer_id = offers.get('offers')[0]['id']
container_launch_info["framework_id"]["value"] = framework_id
container_launch_info["accept"]["offer_ids"].append(offer_id)
task_infos = container_launch_info["accept"]["operations"][0]["launch"]["task_infos"][0]
task_infos["agent_id"]["value"] = agent_id
task_infos["task_id"]["value"] = task_id
task_infos["resources"].append(get_json(TASK_RESOURCES_JSON))
The code above does the following:
- load the
DOCKER_JSONfile and build adictout of it; - extract the
agent_idandoffer_idfrom theOFFERSresponse we received on the “streaming” channel (see thepost()method, as well as the full breakdown of the response in the notebook output – this was described in Part 2) and put them back in our request: this will enable Master to reconcile the two: failing to do so, will cause Master to refuse the request; - finally, take a reference to the
task_infofield of the request, and then update its fields to contain theagent_idandtask_id(this is just a convenience to avoid some typing and a very long statement).
Task ID
You may have noticed this strange line in the snippet above:
task_id = str(random.randint(1, 100))
The TaskID is used by the Agent to uniquely identify the tasks from a framework and it’s also meant for the users (“operators”) to be able to track tasks that are launched on Mesos: it can be really anything (Mesos doesn’t care, so long as it’s unique per framework) and you will see its use in a second.
I have chosen to use a random integer between 1 and 100, but note Mesos expects a field of type string, so we convert it via the str() method.
Launching a container
With all the above done, it’s time to fire it off:
r = post(API_URL, container_launch_info)
which is a bit of an anti-climax, but will result (unless you’ve messed around with the JSON format and made it fail some syntax check or the conversion to Protocol Buffer, the format used internally by Mesos) in a
Connecting to Master: http://192.168.33.10:5050/api/v1/scheduler
body type: ACCEPT
Result: 202
Note that you will get a 202 regardless of whether the task was successfully launched, or failed post launch, or anything else, for that matter, that could have happened to it.
As mentioned in the previous post, the API model is an asynchronous one and you will get the actual outcome of your request (beyond a simple syntactic validation) over the “streaming” channel (the equivalent of the callback methods of the original C++ Scheduler API).
In a “real life” Framework, after sending a request to launch a task, we would wait for an “event” posted back by the Master and specifically wait for an UPDATE or a new OFFER message to discover whether the task was successfully launched or had failed.
See the Scheduler API for more details and a full list of messages and events.
For our part, we will explore the success (or otherwise) of our launch by using the Master UI:
http://192.168.33.10:5050
should show a list of Active/Completed/Orphan tasks and, with any luck, a new one should be listed in the Active pane, with TASK_RUNNING status:

Alternatively, you can click on the Agents button on the tab bar at the top and then follow the link to the one running agent, to see a list of Frameworks whose tasks are running on the Agent:

and clicking on the active one (you can see I’ve been experimenting…) take you to a list of “Executors”(1)

where you can see the task just launched (notice the ID – this is where we would see whatever we were to set for the task_id: in our case just an integer under 100):
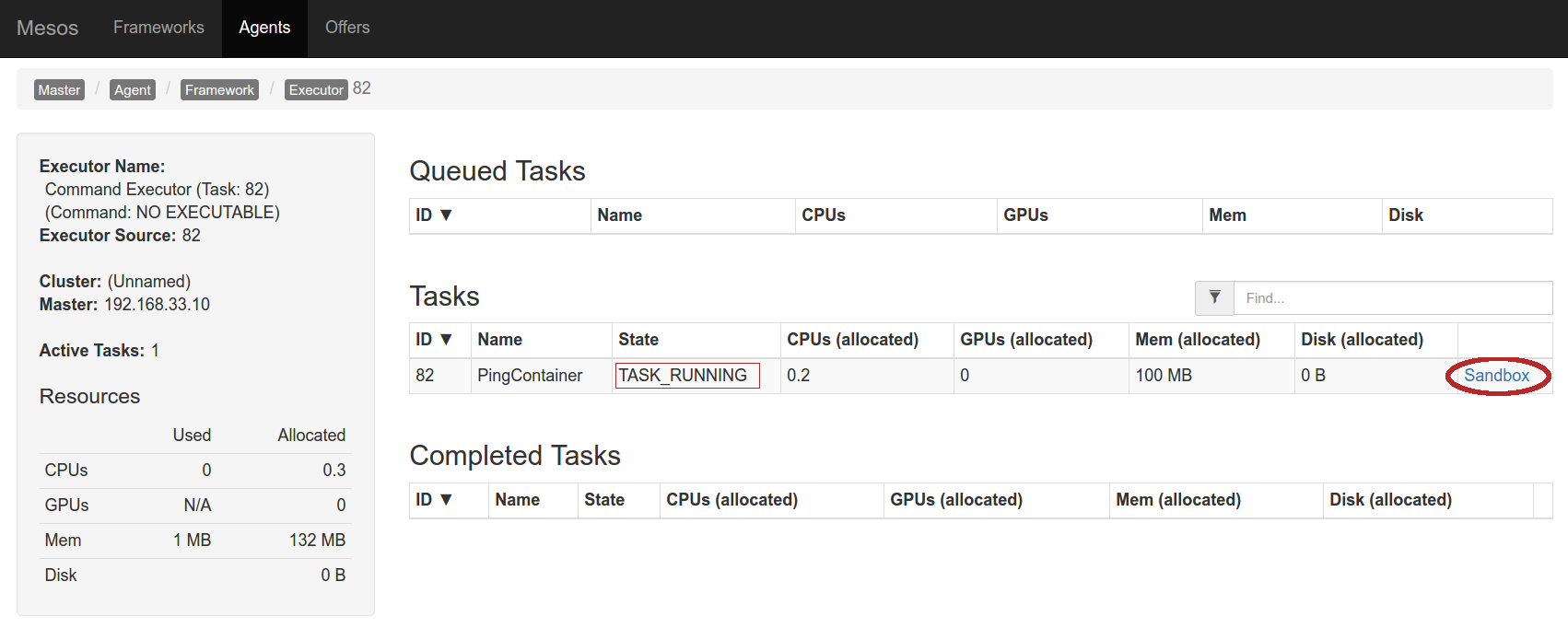
and, finally, we could hit the Sandbox link to look at the STDOUT/STDERR from the task execution.
Notice how we only requested a tiny fraction of what we were offered: just 20% CPU and 100MB of RAM – and, in fact, using even less.
The requested resources were defined in the "resources" field:
task_infos["resources"].append(get_json(TASK_RESOURCES_JSON))
and are defined in the resources/task_resources.json file:
[
{
"name": "cpus",
"role": "*",
"scalar": {"value": 0.2},
"type": "SCALAR"
},
{
"name": "mem",
"role": "*",
"scalar": {"value": 100},
"type": "SCALAR"
}
]
If all looks well and the task is in the TASK_RUNNING state (if not, there is a “Troubleshooting” section at the end), you should be now able to access the just-launched Nginx server on it default HTTP (80) port:
http://192.168.33.11
Notice how this is the Agent’s IP address not the Master: the container is running on the Agent and using its resources:
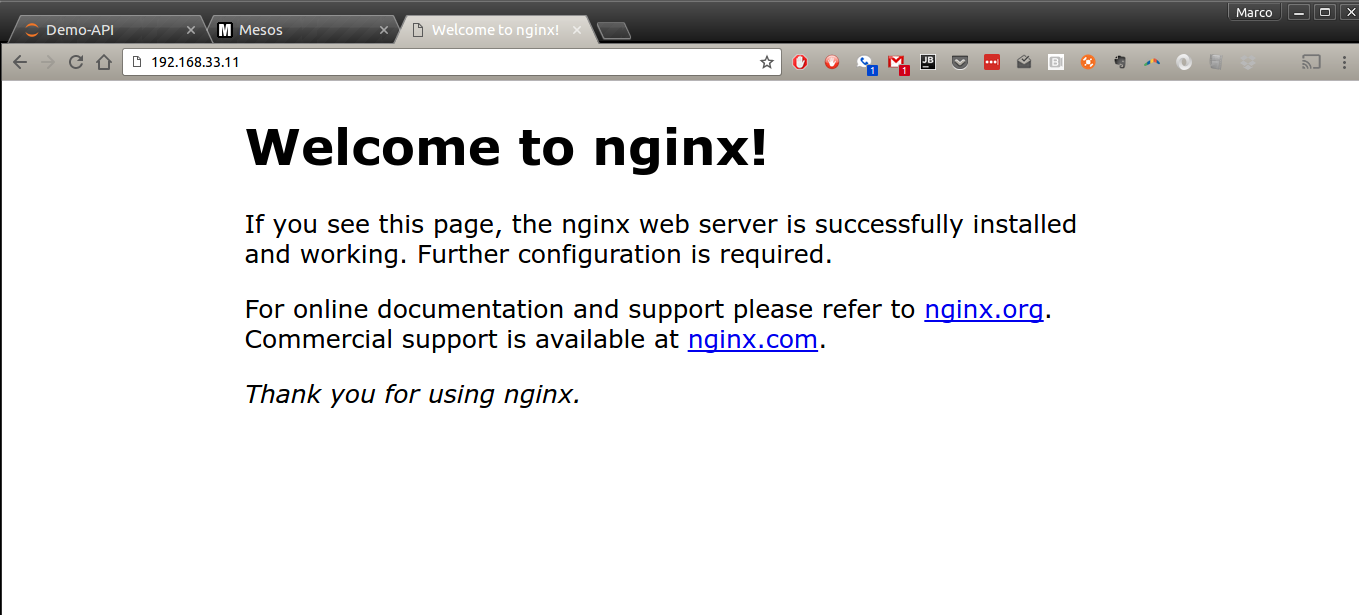
Obviously, this just shows the default page: in a real live situation, we would use two possible alternative approaches:
- build our own container image, with the desired static pages (and whatever other custom Ngnix configuration made sense) and possibly even with some proxying logic to a dynamic online app;
-
download and extract a tarball with the website’s static contents (not just HTML/CSS but Javascript too, possibly), as described below.
Downloading content to Mesos Agents
One of the fields of the Accept Protocol Buffer is an Offer.Operation which in turn can be of several “types”, one of which (LAUNCH) implies that its content are a ‘Launch’ message, in turn containing an array (or list if you are into C++) of TaskInfo dictionaries, which in turn contain a (required) CommandInfo field, called "command".
If you are not confused yet, you’ve not been following closely… but the bottom line is, at any rate, that by setting the content of command to something like this:
...,
"command": {
"uris": [
{
"value": "http://192.168.33.1:9000/content.tar.gz",
"extract": true
}
],
"shell": true,
"value": "cd /var/local/sandbox && python -m SimpleHTTPServer 9090"
},
...
we can specify a list of URIs (which must be reachable by the Agent) whose contents will be fetched and, optionally (if extract is true) uncompressed into the container “sandbox”: the field we have specified at launch with (see the run_agent.sh script):
--sandbox_directory=/var/local/sandbox
This finally closes this, admittedly convoluted, detour: if we were to configure our Ngnix server (or whatever other application we were to launch) to use that directory as the source for the site pages, those would be served instead.
An example of how to do this using a much simpler Python SimpleHTTPServer is demonstrated alongside the alternative method of executing a command on the Agent (as opposed to launching a container – the dynamic of downloading a remote file remains the same) in the notebook’s section called “Launch a Task using the given offers”.
This will require that you somehow set a server up to serve the content.tar.gz file on your local dev box (or wherever you feel like – an AWS S3 bucket would be a perfect candidate for this in a real production environment) and changing the JSON in the request to use resources/container.old.json in the repository, which is maybe a good “exercise for the reader,” but maybe one step too far for some.
A couple of considerations:
- a recently implemented feature allows Mesos to cache content downloaded dynamically (including container images): for more information, please see the Fetcher Cache excellent document;
-
directly launching a binary on an Agent (as opposed to downloading and running a container image) runs counter, in my view, to the whole spirit of treating your machines “as a herd, not a pet” in a modern, DevOps-oriented production environment: this requires to choose between to equally bad options:
- use some form of packaging and configuration management (e.g., Chef or Puppet) to ensure all your Agents have the same set of binaries and will be able to run them upon request; or
-
use a (possibly, cumbersome) combination of roles and attributes (see Part 2) to ensure frameworks are only able (or allowed) to launch certain binaries on certain agents (in addition to the above provisioning and configuration management approach).
Compared with the simplicity of having a cluster (possibly, running in the 000’s of machines, all identically provisioned) and letting Mesos just pick one for you and then download and run a container (again, possibly, from a private image registry, managed via a CI/CD infrastructure), it seems to me a much more scalable, agile and definitely less error-prone approach.
But, there you have it: in case you wish to run a binary, the code for how to do it is shown there.
Troubleshooting
If your Master server dies, or you can’t launch the container, there are a few steps that I’ve found useful when creating the code and this blog entry:
1. restart the Master:
cd vagrant
vagrant ssh master
ps aux | grep mesos | grep -v grep
# Is there anything running here? if not:
sudo ./run-master.sh
# you can happily ignore Docker whining about ZK already running (also see below)
2. is Zookeeper still alive?
cd vagrant
vagrant ssh master
sudo docker ps
# is the zk container running? if not, you can restart it:
sudo docker rm $(sudo docker ps -qa)
sudo docker run -d --name zookeeper -p 2181:2181 \
-p 2888:2888 -p 3888:3888 jplock/zookeeper:3.4.8
# Alternatively, as ZK going away means that usually Master terminates too, use
# the solution above to restart Master.
3. Is the Agent active and running?
Start from http://192.168.33.11:5051/state – if nothing shows, then follow a similar solution as to the above to restart the agent:
cd vagrant
vagrant ssh agent
ps aux | grep mesos | grep -v grep
# Is there anything running here? if not:
sudo ./run-agent.sh
Head back to your browser and check whether the UI is responsive again.
If the server is running but unresponsive, or seems to be unable to connect to the Agent or whatever, you can just kill it:
ubuntu@mesos-master:~$ ps aux | grep mesos | grep -v grep
root 18630 0.0 4.3 1318424 43728 pts/1 Sl 20:29 0:02 mesos-master
ubuntu@mesos-master:~$ sudo kill 18630
(and resort to a -9, SIGKILL if it really has become completely unresponsive).
4. Keep an eye on the logs
As mentioned also in Part 2, it is always useful to keep a browser window open on the Master and Agent logs – this can be done via the LOG link in their respective UI pages:

They usually provide a good insight into what’s going on (and what went wrong); alternatively, you can always less them in a shell (via the vagrant ssh shown above): the log directories are set in the launch shell scripts:
# In run-master.sh:
LOG_DIR=/var/local/mesos/logs/master
# In run-agent.sh
LOG_DIR=/var/local/mesos/logs/agent
and you will something like this (I usually find the INFO logs the most useful, YMMV):
ubuntu@mesos-master:~$ ls /var/local/mesos/logs/master/
mesos-master.ERROR
mesos-master.INFO
mesos-master.mesos-master.root.log.ERROR.20160828-211508.2991
mesos-master.mesos-master.root.log.ERROR.20160902-080919.17820
mesos-master.mesos-master.root.log.INFO.20160827-210041.30302
mesos-master.mesos-master.root.log.INFO.20160828-210703.2991
mesos-master.mesos-master.root.log.INFO.20160902-054452.17820
mesos-master.mesos-master.root.log.INFO.20160903-202955.18630
mesos-master.mesos-master.root.log.WARNING.20160827-210041.30302
mesos-master.mesos-master.root.log.WARNING.20160828-210703.2991
mesos-master.mesos-master.root.log.WARNING.20160902-054452.17820
mesos-master.mesos-master.root.log.WARNING.20160903-202955.18630
mesos-master.WARNING
Note that the mesos-master.{ERROR,INFO,WARNING} are just symlinks to the files being currently appended to by the running processes.
5. Dammit, all else failed!
Ok, time to bring the heavy artillery out: destroy the boxes and rebuild them from scratch:
cd vagrant
vagrant destroy
vagrant up
this is nasty and time-consuming, but it guarantees a clean slate and should set you back into a working environment.
Conclusion
This has been a long ride: between updating the Python notebook, creating and fine-tuning the Vagrant boxes and drafting these blog entries, it has taken me almost a month and many hours of experimenting with Mesos and its HTTP API.
It has been overall a fun experience and I believe it has helped me learn more about it; it also provides a good foundation upon which to build a Python library to abstract much of the low-level complexity: I will continue to work and update the zk-mesos repository; please come back from time to time to check on progress or, even better, feel free to fork and contribute back your code via pull requests.
Just remember, no smelly code!

Leave a comment